
If you've got a large dataset of open-text responses, it might be tempting to just break it into chunks and pass to an LLM to find out roughly what themes or topics are in there. But taking this approach can lead to some very biased estimates of what's in your dataset.
This isn't a new AI challenge. It's a statistical problem with a long history.
In the early 1970s, researchers analysing graduate admissions at University of California, Berkeley appeared to find clear evidence of gender bias in favour of men. But when they broke the data down by department, the pattern flipped: most departments let in a higher percentage of women.
What was going on? It turned out women tended to apply for the more competitive departments (i.e. lower admission %) and men the easier ones (i.e. higher admission %). So when the data was aggregated across the university, it looked like there was a bias in overall admissions.
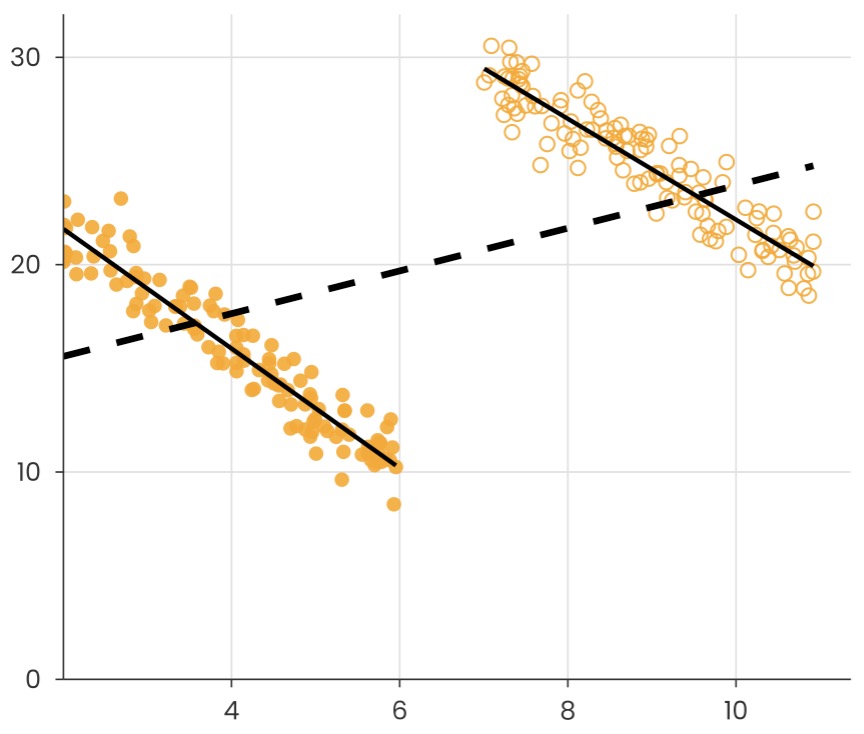
It was a textbook example of what's known as 'Simpson's paradox': trends in groups of data can disappear or switch depending on how groups are combined.
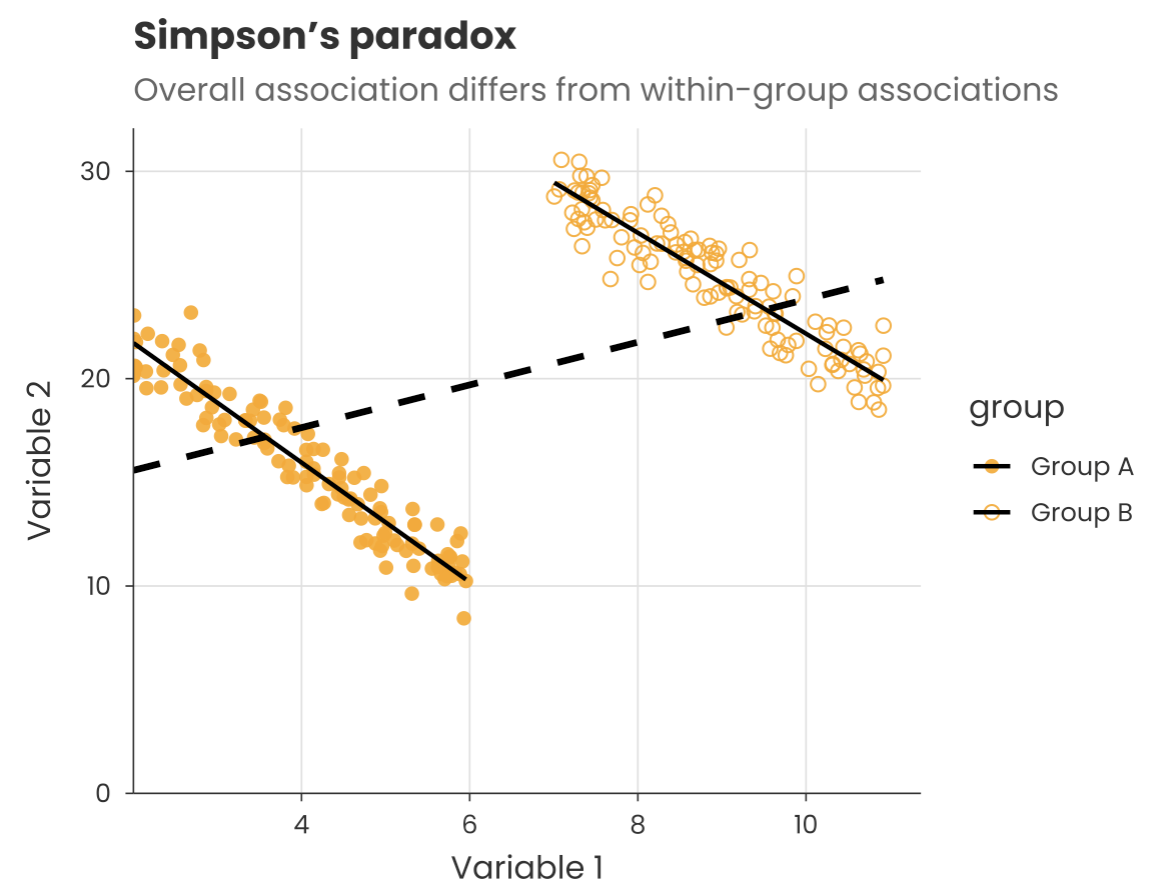
The same issue crops up with LLM-based theme extraction. When you chunk text and ask AI what's in there, the responses will 'compete' with whatever is in their chunk. This can systematically skew which themes appear prominent, in ways that won't be obvious from the outputs alone.
Language models can be powerful tools. But without careful statistical handling, they can introduce exactly the kind of paradoxical bias that researchers have been warning about for decades.