

Large language models are good at a lot of things, but reliable numerical reasoning isn’t one of them. Many of our early users tried ChatGPT, Claude, or other LLMs to analyse open-ended survey responses and soon ran into a problem: they didn’t trust the numbers.
They were right to be sceptical.
LLMs can perform well on some tasks, only to fall apart on others, especially as the scale increases. Take the following counting task. If we give GPT-4.1 a dataset containing 50 unambiguous statements like “I am feeling positive” or “I am feeling negative”, it will generally lands in the right ballpark. But increase that to 500 or 1,000 responses and the model can start doing strange things.
The plot below shows just how extreme the errors can become:
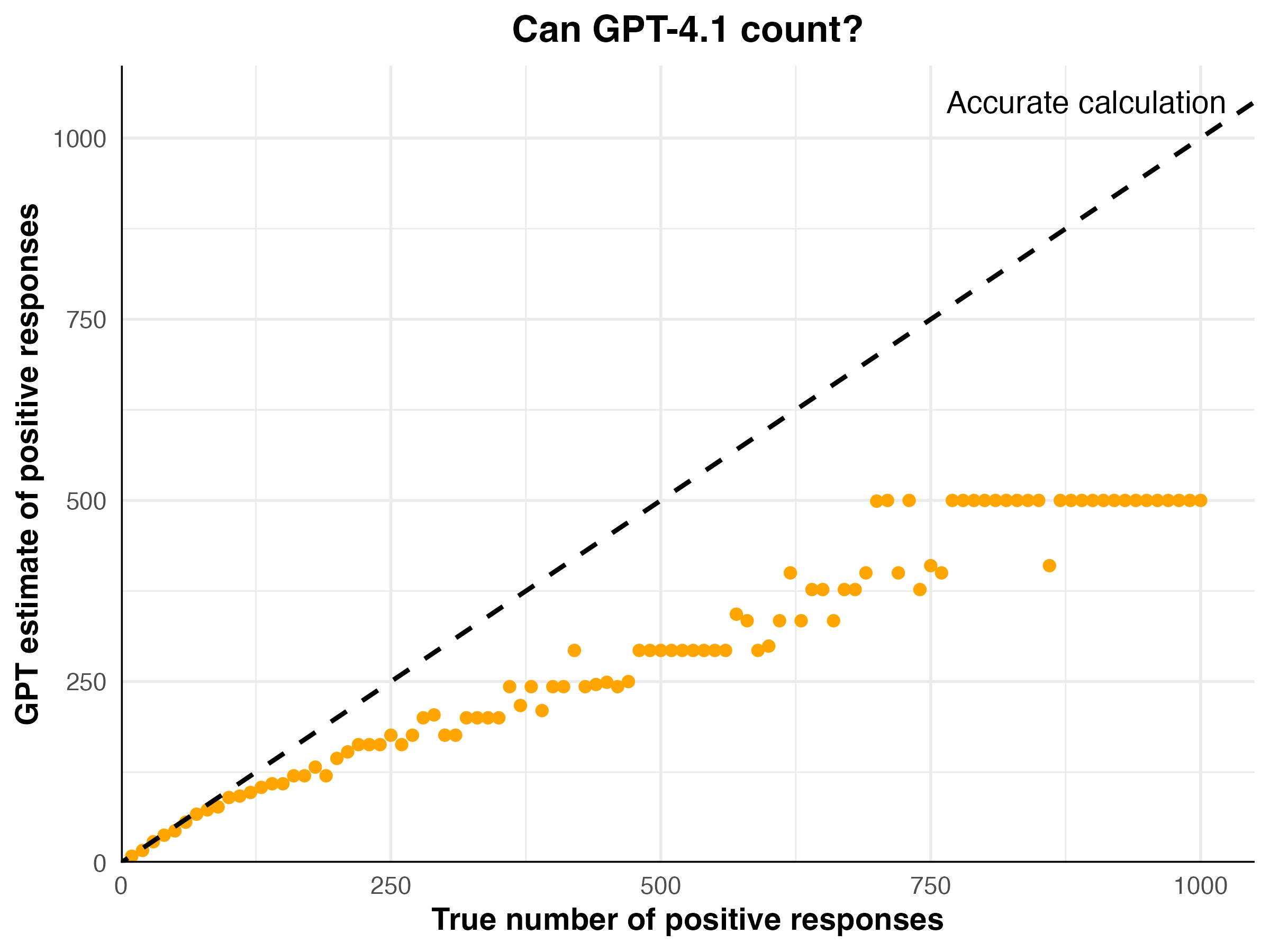
This is the kind of task a human could do perfectly given enough time and patience. But the model’s accuracy gets worse as the dataset grows, and the output often sticks at the same value no matter what the input is.
This aligns with what one research director told us: "The more data I put into ChatGPT, the worse it gets."
This is why we built WholeSum. Our approach keeps every numerical operation outside the generative model. Counting is handled by non-LLM logic, so the correct result stays correct whether you’re dealing with 50 responses or 50,000.
Even the latest models can struggle with seemingly simple tasks. For example, this is what we got when we gave GPT-5 and Claude Sonnet 4.5 a small JSON table and asked it to sum up the rows and columns:
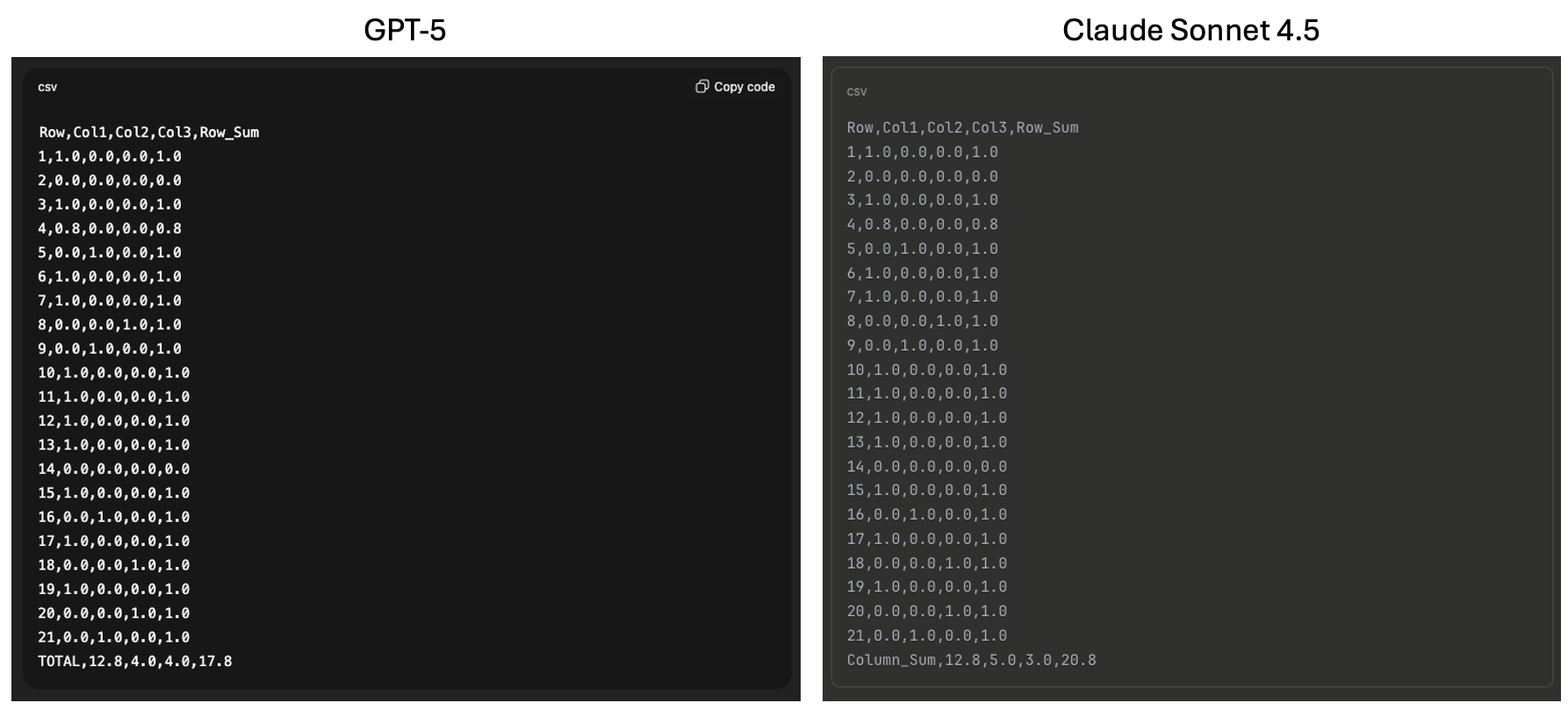
Both returned incorrect totals for this simple input. Even though GPT-5 and Sonnet have the ability to call tools like Python, the generative language model that orchestrates the task introduced an error at some point.
The totals above might look superficially plausible, but you'd definitely want to double check them before doing anything else. Which creates an enormous human-in-the-loop bottleneck if you're doing tasks frequently.
WholeSum removes this bottleneck. Numerical calculations never pass through a generative model, so the final output reflects the structure of the original data and any analysis performed. When there’s a ground truth, you should get it every time.
Indeed, that’s the reason we’re called WholeSum.