
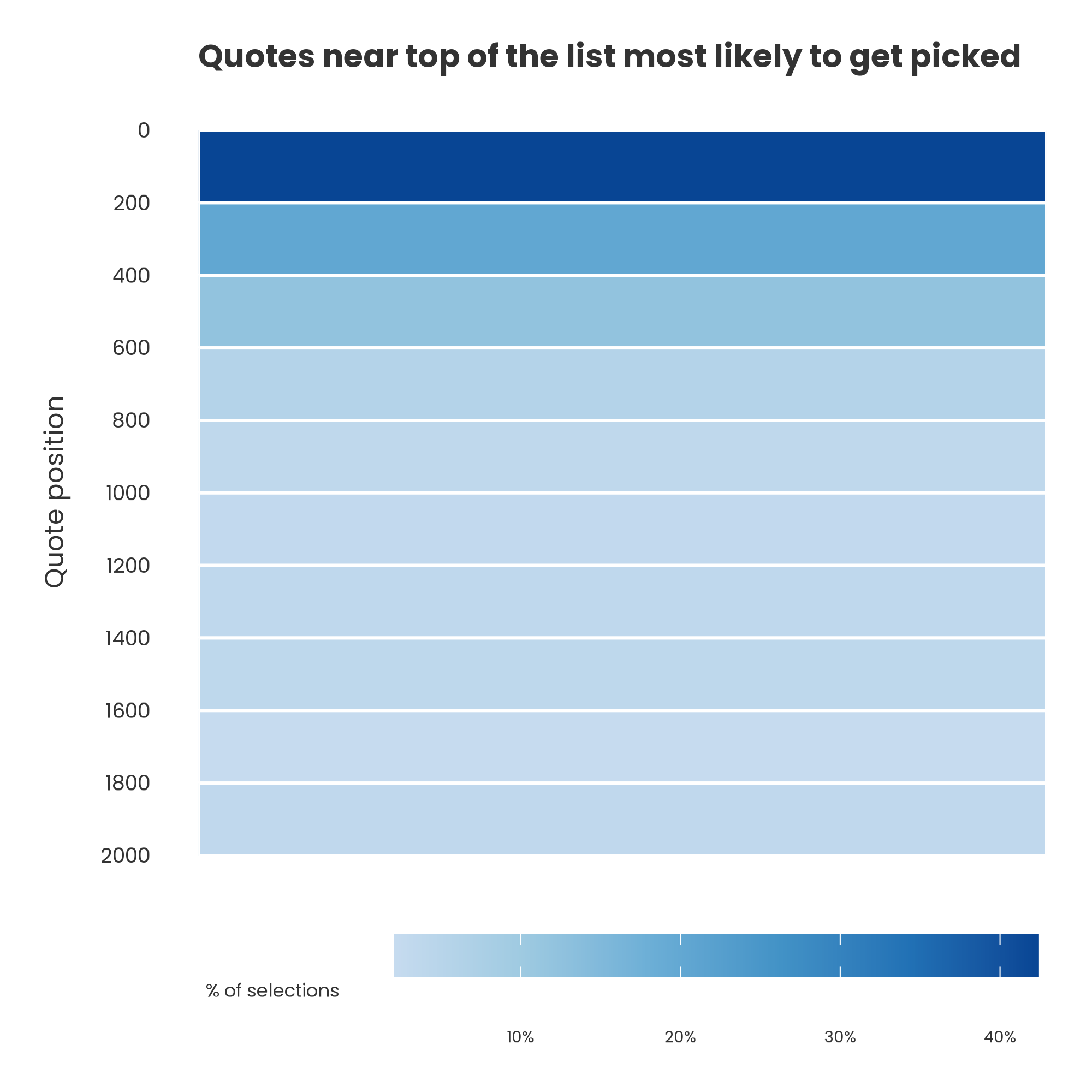
AI doesn't always view data in the way we think it might. For example, we gave the new Claude Sonnet 4.6 a set of 2000 short literary quotes and asked it to output the 10 most profound from this list. Most of the ones it returned appeared very early on in the dataset.
Perhaps the profound quotes genuinely happened to be near the top? To test this, we randomly shuffled the dataset and repeated the analysis 100 times. This removed any 'position bias' effect – quotes appeared in different positions on each run.
But even after shuffling, the same pattern emerged: the quotes that happened to appear earlier in the model's input were much more likely to be selected.
This is a structural feature of LLMs like Claude: they tend to focus attention on the early part of a dataset. Even with large 1m token context windows in theory, not all parts of a dataset influence the output equally in practice.
Language models can be powerful tools, but without careful design and adjustment, you may well end up only seeing a small part of the true picture.
(As a footnote: 12/100 runs contained a quote that wasn't in the original dataset at all. Claude seemed to be a particular fan of inserting some Orson Welles into the list: "We are born alone, we live alone, we die alone. Only through our love and friendship can we create the illusion for the moment that we're not alone.")